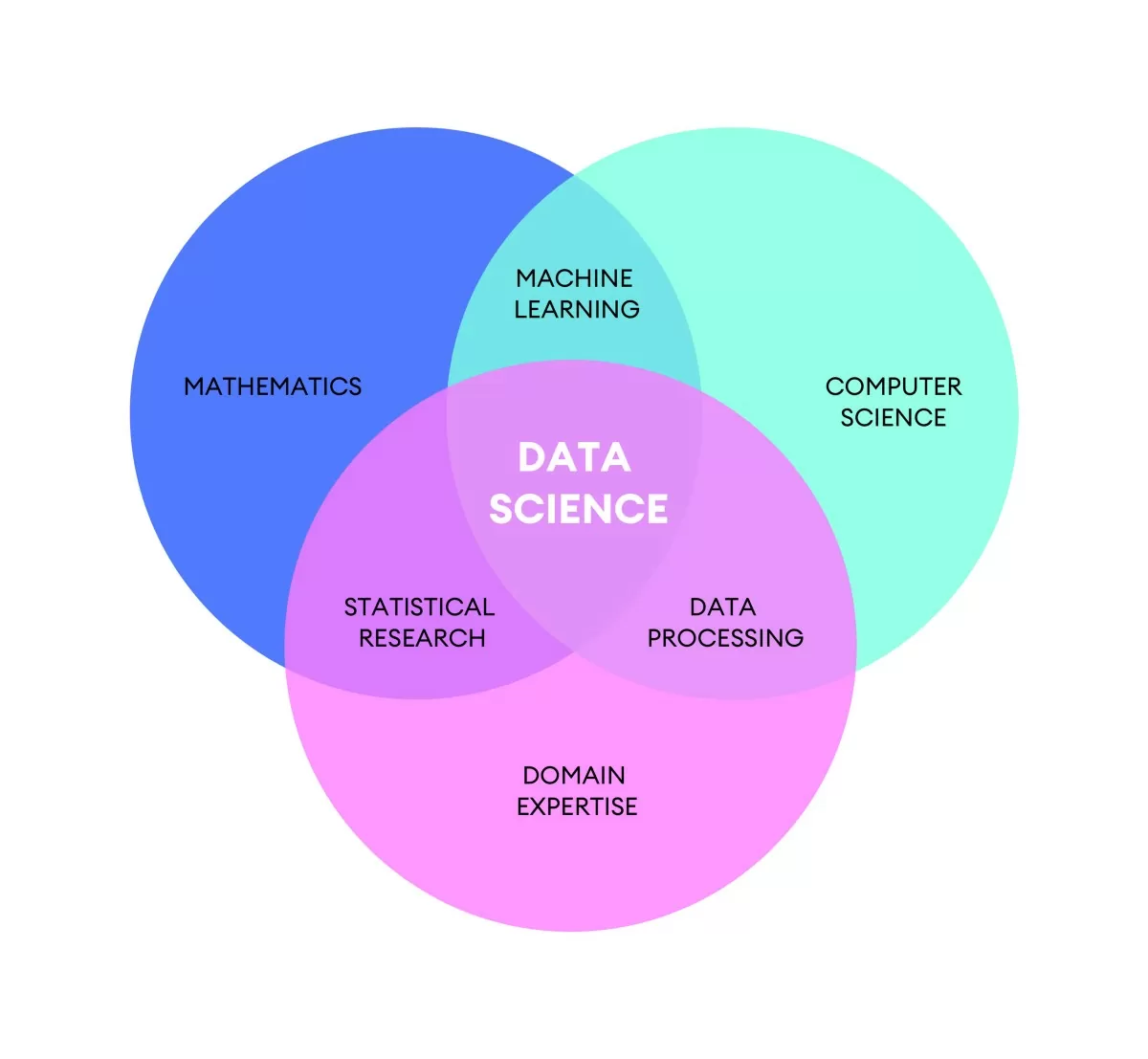
Con il termine Data Science si intende una disciplina che si occupa di elaborare e interpretare i dati. La disciplina Data Science nasce dalla convergenza di molte conoscenze che vanno dalla Statistica alla Matematica, dalle Scienze all’Informatica.
La Data Science, ovvero la Scienza dei Dati, è una scienza relativamente nuova, infatti esiste da una cinquantina d’anni. Nasce dall’esigenza di mettere ordine in un contesto molto vivo, in forte evoluzione. La crescita del volume dei dati, la possibilità e la capacità di dare un significato ai dati, hanno reso sempre più importante e articolata la Data Science.
Storicamente parlando il dato è stato spesso trattato come una sorta di prodotto secondario di qualsiasi processo. Chiunque nei secoli si sia impegnato a raccogliere dati, lo ha fatto principalmente per propria comodità, spesso senza immaginare che oggi a una raccolta di dati potrebbe essere attribuito un valore economico. Se pensiamo ad esempio a un’azienda agricola che negli anni potrebbe aver raccolto informazioni sui raccolti, sugli eventi, sulle semine ecc…, magari potrebbe averlo fatto per archiviare la propria storia aziendale. Se tutte le aziende agricole l’avessero fatto che metodo, allora aziende produttrici di fertilizzanti, oggi ne potrebbero trarre vantaggio per scopi di ricerca, o per scopi di marketing.
Data Scientist
Colui che si occupa di Data Science, viene chiamato data scientist: attualmente una delle figure professionali più ricercate nel mondo del lavoro.
Il compito del data scientist è quello di analizzare dati al fine di individuare modelli al loro interno, cioè cosa esprimo i dati a disposizione mediante l’andamento. L’individuazione di questi modelli è funzionale agli scopi del committente: azienda, ente pubblico ecc…
Monetizzazione
Negli ultimi anni si è sempre più affermato un modello di commercializzazione dei dati dove qualcuno è interessato a vendere dati e qualcun altro a comprarli.
Sono nate aziende specializzate nella produzione di dati, e aziende specializzate nella compravendita dopo opportune operazioni di pulizia e rielaborazione. Se poi pensiamo alle normative sulla privacy, ci rendiamo conto della complessità dell’argomento. Oggi esistono leggi severe che richiamano ad un uso consapevole e rispettoso delle informazioni.
Progettualità
Un progetto di Data Science solitamente è composto dai seguenti step:
- Descrizione del problema: un progetto nasce con l’obiettivo di raggiungere un risultato, o di risolvere un problema. In questa descrizione vengono circoscritte le caratteristiche dei risultati che si vogliono ottenere, le tempistiche entro cui conseguirli, e le risorse a disposizione;
- Raccolta dei dati: per affrontare il problema, si dovranno ricavare dei dataset, o già presenti in azienda o da fonti esterne. Si potrebbe trattare di sondaggi on-line, dati raccolti da fonti social ecc… . Questo dataset andrà poi ripulito, ordinato e strutturato in modo tale che diventi la fonte di lavoro del data scientist;
- Esplorazione dei dati di partenza: a questo punto i dati vanno visti ed esplorati, filtrati, riassunti in tabelle e visualizzati in grafici. Tutto ciò consentirà di individuarne le caratteristiche, confini ed eventuali lacune;
- Analisi dei dati: questa è la fase in cui vengono individuati i modelli, utilizzando gli strumenti e le tecniche più idonee in funzione degli obiettivi che si vogliono raggiungere;
- Applicazione dei Modelli: in questa fase finale, l’applicazione dei modelli individuati consentirà di ottente i risultati voluti. Qui il data scientist si limita a dare le linee guida per l’utilizzo del data set, e l’estrapolazione delle informazioni corrette. Tali linee guida dovranno essere espresse con il linguaggio di business dell’azienda, che serviranno a risolvere le problematiche per cui il progetto è stato sviluppato.
In ogni singolo passo il data scientist interagisce con dipartimenti specifici aziendali, e quindi possiamo dire che il data scientist è perfettamente calato nella realtà aziendale.
Con il progresso tecnologico, il data scientist si è spesso trovato ad affrontare problematiche di Big Data e Intelligenza Artificiale.
Big Data
Quando si parla di Big Data ci si riferisce a dati che contengono una grande varietà, che arrivano in volumi crescenti e con maggiore velocità. Questo concetto è anche noto come regola delle tre V, che consiste nella scelta di tre termini che caratterizzano il fenomeno Big Data nei tratti essenziali:
- Volume: perchè la quantità di dati da trattare è estremamente alta. Questo fattore è sicuramente il più indicativo dei tre, infatti alla parola Data è preceduta dall’aggettivo Big. Gli archivi Big Data si misurano nell’ordine dei Terabyte o Petabyte;
- Velocità: questo termine si riferisce alla rapidità con cui i dati vengono accumulati. Sono sempre più comuni i contesti in cui il flusso di dati è continuo, senza sosta, in streaming affluisce sul server. Questo obbliga l’attuazione di sistemi in grado di accumulare senza perdita di dati, senza blocchi e riducendo al minimo i tempi di latenza. Pensiamo ad esempio alle transazioni finanziarie, al trading online, IoT ecc…
- Varietà: a differenza di archivi fortemente strutturati, i dati che fanno parte di un sistema BigData sono molto variegati. Come esempio possiamo pensare ai dati che vengono raccolti in un qualunque social network: foto, testo, allegati, filmati.
In realtà nel tempo si sono aggiunte anche altre particolarità, come la Veridicità dei dati per identificare l’attendibilità e l’affidabilità dei dati.
Grande volume di dati che arrivano a grande velocità, e caratterizzati da grande varietà, portano necessariamente problematiche di organizzazione dei dati.
Come organizzarli ?
Accoglierli e poi elaborarli ? Strutturarli e poi elaborarli ?

Sono nati diversi paradigmi di organizzazione dei sistemi di dati, che si sono affermati nel tempo:
- Datawarehouse: Cioè archivi strutturati di dati. Molto usato, con la particolarità che i dati devono essere organizzati nel momento stesso in cui si ricevono;
- Data Lake: caratterizzato dal fatto che tutti i dati in arrivo vengono accantonati nel contenitore senza alcun criterio di archiviazione strutturata. Paradigma opposto al Datawarehouse, perchè nel Data Lake i dati si andranno a strutturare solo quando è necessario leggerli per interpretarli. Questo approccio semplifica e velocizza la fase di acquisizione, a discapito delle fasi successive;
- Silos: detto anche a compartimenti stagni. Ogni dipartimento o reparto aziendale accumula i propri dati senza condivisione con gli altri.
Attualmente questi sono i paradigmi maggiormente usati, e in molti casi prevale la soluzione dell’integrazione, cioè diversi progetti potrebbero usare metodologie di accumulo diverse per poi integrarsi in un secondo momento. Si potrebbero avere situazioni in cui si raccolgono dati diversi con paradigmi diversi, oppure diverse raccolte potrebbero costituire fasi attigue di uno stesso ciclo di vita.
Machine Learning
Nonostante la loro grande utilità, sappiamo benissimo che le macchine elaboratrici o computer, sono stupidi. Cioè un computer non sa fare niente se non è l’essere umano ad analizzare un problema, formulare un algoritmo e codificarlo in un programma.
Così è sempre stato, finchè non si è iniziato a parlare di Intelligenza Artificiale. Infatti l’intelligenza artificiale consiste nell’indurre una specie di ragionamento spontaneo nella macchina, che la possa portare a risolvere problemi in autonomia, cioè senza diretta guida dell’uomo.
Ci sono voluti diversi anni prima di concretizzare l’espressione “indurre una specie di ragionamento spontaneo nella macchina“, cioè ci sono voluti diversi anni prima che si passasse da una condizione di totale istruzione “forzata” della macchina, ad una condizione di auto apprendimento. Cioè si è riusciti a mettere in condizione la macchina di auto apprendere, di imparare. Si è quindi arrivati al Machine Learning.
Il Machine Learning è una branca dell’Intelligenza Artificiale in cui il programmatore guida la macchina in una fase di training basata sullo studio di dati storici. Terminata questa fase di training, viene prodotto un modello che può essere applicato nella risoluzione di problemi, esplicitati con dati nuovi.
Rispetto l’approccio classico, in cui il data scientist lavorava per definire algoritmi risolutivi, sarà la macchina a scoprire cosa compone il modello. Il Data Scientist si deve occupare di organizzare fasi di training sempre più efficaci, con dati più ricchi e significativi, e di verificare la bontà dei modelli prodotti sottoponendoli ai test.
Grazie al Machine Learning, i sistemi che utilizziamo nei dispositivi mobili, internet, domotica sono (o sembrano) sempre più intelligenti. Un sistema, man mano che lavora, potrebbe essere in grado anche di raccogliere dati su di esso e sugli utenti che lo utilizzano, utilizzandoli poi in fase di training per poi ulteriormente migliorare le previsioni.
Ercole Palmeri: Innovation addicted